
Research
Overview of the Lab
This research lab is now closed.
The Computational Cognition and Perception Lab uses experimental and computational methodologies to study human learning, memory, and decision making in cognitive and perceptual domains. How is new information—such as a visual feature distinguishing the appearances of identical twins or a combination of features allowing a person to identify or categorize novel objects—acquired and how does this information become established in memory? How are perceptual learning and memory similar or different from cognitive learning and memory? How is low-level perceptual information abstracted to form the basis of high-level conceptual information? To what extent are people's behaviors consistent with the optimal behaviors of computational models based on Bayesian statistics? Our research lab addresses these and other questions.
Research Data Sets
See & Grasp Data Set
The See & Grasp Data Set contains both visual and haptic features for a set of objects known as Fribbles. It is described in Yildirim & Jacobs (2013), and can be accessed from here.
See & Grasp 2 Data Set
The See & Grasp 2 Data Set contains visual, haptic features, 3D model files and sample rendering code for the whole set of objects known as Fribbles. Differently from See & Grasp Data Set, this dataset contains all of the objects in the Fribbles dataset from TarrLab. Please click here to access the dataset.
Selected Research Projects
Multisensory Perception
Human perception is fundamentally multisensory. We learn about our environments by seeing, hearing, touching, tasting, and smelling these environments. Moreover, evolution has designed our brains so that our senses work in concert. Objects and events can be detected rapidly, identified correctly, and responded to appropriately because our brains use information derived from different sensory channels cooperatively. This fundamental property of human perception is a key reason that human intelligence is so robust.
We've been interested in cross-modal transfer, exhibited when a person uses information obtained through one sensory modality to enhance performance in environments in which information is obtained through other modalities. For instance, if people learn to visually categorize a set of objects, then they can often categorize these objects when the objects are touched but not seen. How is this possible? We hypothesize that people use their sensory-specific object representations, such as visual object representations or haptic object representations, to acquire abstract representations of objects—representing objects' parts and their spatial relations—that are modality-invariant. These abstract or conceptual object representations mediate the transfer of knowledge across sensory modalities. Experiments are conducted to test this hypothesis. Computational models use Bayesian inference to implement and evaluate this hypothesis.
Our work has made use of a class of objects known as Fribbles. In the figure below, the top row shows computer-generated images of Fribbles. These images were rendered using the Fribbles' 3-D object models. The bottom row shows photographs of the physical objects corresponding to these same Fribbles. These objects were fabricated via a 3-D printing process using the same 3-D object models.


Visual Short-Term Memory
Visual short-term memory (VSTM) — defined as the ability to store task-relevant visual information in a rapidly accessible and easily manipulated form — is a central component of nearly all human activities. It plays a critical role in online movement control, integration of visual information across eye movements, and visual search. We've been interested in a number of properties of VSTM. For example, VSTM seems to have a limited capacity, meaning that it can store only a finite amount of information. What are the capacity limits of VSTM and how should these limits be quantified? We've been using an approach based on information theory to address these questions. As a second example, our memories of recent visual events are often incorrect. These memories show biases and dependencies. What is the nature of these biases and dependencies, and why might memory representations with biases and dependencies be a good idea? We've been using experimentation and computational modeling to address these questions.
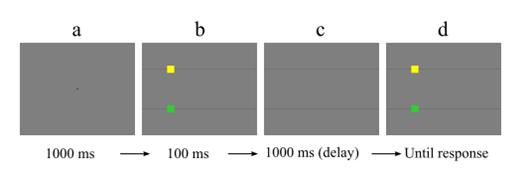
The image below shows a trial from one of our experiments. Subjects first fixate a small cross at the center of the screen. They then briefly see a screen with two squares, see a blank screen, and then see another screen with two squares. They need to judge whether the positions of the squares are the same or different in the first and second screens containing the squares.
Effective Perceptual Learning Training Procedures


It has often been noticed that motor training in adults often leads to large and robust learning effects whereas visual training often leads to relatively small learning effects. To date, it is not known if the limited effects of visual training in adults are due to inherent properties of our visual systems or, perhaps, due to our immature knowledge of how to optimally train people to improve their perceptual abilities. It may be the case that if we learn more about how to train people's visual systems, then visual therapy in the near future could be as effective as physical therapy is today. Our lab is studying new ways of training people to perform perceptual tasks. One hypothesis that we are examining is that people will learn best when they are in environments that are as natural as possible. For example, people should not only be able to see objects, but also to touch and move objects. Sophisticated virtual reality equipment allows us to create experimental environments that allow people to see, touch, and hear "virtual" objects.
The University of Rochester has fantastic virtual reality equipment. The figure on the top shows a subject using the "visual-haptic" virtual reality environment. In this environment, a subject can both see and touch objects. The figure on the bottom shows a subject using the "large field of view" virtual reality environment. Subjects in this environment are presented with visual stimuli spanning a full 180 degrees.
Perceptual Expertise
Nearly all adults are visual experts in the sense that we are able to infer the structures of three-dimensional scenes with an astonishing degree of accuracy based on two-dimensional images of those scenes projected on our retinas. Moreover, within limited sub-domains such as visual face recognition, nearly all of us are able to discriminate and identify objects whose retinal images are highly similar. As remarkable as our visual abilities are, perhaps more impressive are the abilities of special populations of individuals trained to make specific visual judgments which people without such training are unable to make. For example, radiologists are trained to visually distinguish breast tumors from other tissue by viewing mammograms, geologists are trained to visually recognize different types of rock samples, astronomers are trained to visually interpret stellar spectrograms, and biologists are trained to visually identify different cell structures. What is it that experts in a visual domain know that novices don't know?
To address this question, we've been training people to discriminate visual objects with very similar appearances. For example, the image below shows a sequence of objects that gradually morph from one shape to another. People initially find it difficult to distinguish similar shapes, but rapidly learn to do so with modest amounts of training.

Computational Models Known as Ideal Observers and Ideal Actors
 Ideal Observers and Ideal Actors are computational models based on Bayesian statistics that perform in an optimal manner. Ideal Observers make statistically optimal perceptual judgments, whereas Ideal Actors make optimal decisions and actions. Our lab is interested in using techniques from the machine learning and statistics literatures to develop new ways of defining Ideal Observers and Actors for interesting tasks. Once an Ideal Observer or Actor is defined, we can run experiments with people using the same tasks. This allows us to compare human and optimal performances. Do people perform a task optimally? If so, then we can conclude that people are using all the relevant information in an efficient manner. If not, then we can examine why they are sub-optimal and what can be done to improve their performances.
Ideal Observers and Ideal Actors are computational models based on Bayesian statistics that perform in an optimal manner. Ideal Observers make statistically optimal perceptual judgments, whereas Ideal Actors make optimal decisions and actions. Our lab is interested in using techniques from the machine learning and statistics literatures to develop new ways of defining Ideal Observers and Actors for interesting tasks. Once an Ideal Observer or Actor is defined, we can run experiments with people using the same tasks. This allows us to compare human and optimal performances. Do people perform a task optimally? If so, then we can conclude that people are using all the relevant information in an efficient manner. If not, then we can examine why they are sub-optimal and what can be done to improve their performances.
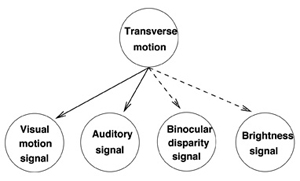
One way in which we create Ideal Observers or Ideal Actors is through the use of Bayesian Networks. An example of a Bayesian Network is illustrated on the left. Bayesian Networks are useful for defining the relationships among a set of random variables, such as the relationships among scene variables (describing what is in an environment) and sensory variables (describing what is in a retinal image, for example).
Cognitive Models and Machine Learning
 It's often useful to implement a cognitive or perceptual theory as an explicit computational model, and to simulate the model on a computer. Doing so forces a person to explicitly work out the details of the theory, and allows the person to carefully evaluate the theory's strengths and weaknesses. Our lab frequently builds computational models based on techniques developed in the machine learning and artificial intelligence communities. These techniques often perform functions relevant to cognitive processing, such as learning, dimensionality reduction, clustering, time series analysis, or classification, in a mathematically principled way.
It's often useful to implement a cognitive or perceptual theory as an explicit computational model, and to simulate the model on a computer. Doing so forces a person to explicitly work out the details of the theory, and allows the person to carefully evaluate the theory's strengths and weaknesses. Our lab frequently builds computational models based on techniques developed in the machine learning and artificial intelligence communities. These techniques often perform functions relevant to cognitive processing, such as learning, dimensionality reduction, clustering, time series analysis, or classification, in a mathematically principled way.
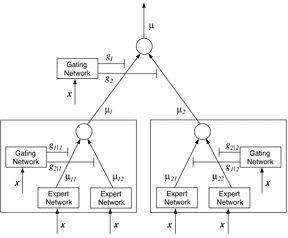
An example of a computational model that we and our colleagues developed is illustrated on the left. It's known as a "hierarchical mixtures of experts." We were interested in the optimal organization of a cognitive architecture. In particular, we wanted to know whether it's preferable to have a highly modular computational system in which different modules perform different tasks or if it's preferable to have a single monolithic system that performs all tasks. The model consists of multiple learning devices, such as multiple artificial neural networks. The model's learning algorithm uses a competitive learning scheme to adaptively partition its training data so that different devices learn different subsets of data items. When different devices learn from different data sets, they acquire different functions. Hence, the model acquires functional specializations during the course of learning.